


|
个人信息Personal Information
教师英文名称:Wei-Qiang Zhang
教师拼音名称:Zhang Wei Qiang
电子邮箱:
办公地点:电子工程馆5-111
联系方式:010-62781847
学位:博士学位
毕业院校:清华大学
学科:信号与信息处理
当小语种遇上大模型:自监督预训练模型显著提升低资源小语种语音识别性能
点击次数:
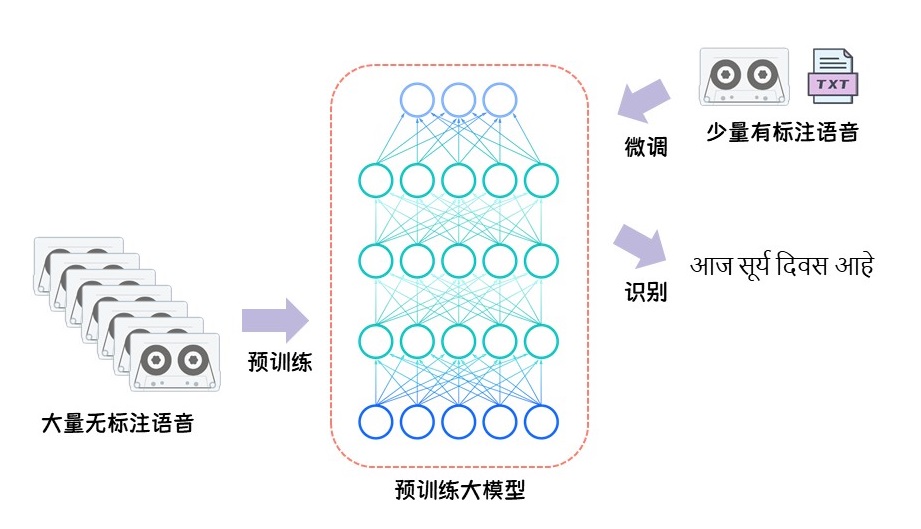
在大规模数据和算力的支撑下,语音领域自监督预学习取得了突破性进展,预训练模型则凭借其优异的性能而备受关注。本文将一系列大规模预训练模型进行了深入对比,针对低资源小语种自动语音识别这一下游任务展开探索,并从模型、方法、语种等多个角度全面分析并总结了性能差异和内部机理。日前,该工作已被IEEE信号处理协会顶级期刊IEEE Journal of Selected Topics in Signal Processing接收。
J. Zhao and W.-Q. Zhang, “Improving automatic speech recognition performance for low-resource languages with self-supervised models,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1227–1241, Oct. 2022. doi: 10.1109/JSTSP.2022.3184480.
背景
近期语音自监督学习凭借其在多个下游任务中的出色性能而备受关注,这为低资源语种语音识别带来了新的发展空间。本文中,我们对比分析了多个wav2vec系列预训练模型在15个不同的低资源小语种上的表现。研究内容主要针对模型预训练阶段的两个重要因素(模型框架和训练数据)、三种微调方法以及预训练模型表征应用展开。首先,我们研究了使用不同语音数据或自监督架构(wav2vec2.0、HuBERT和WavLM)的预训练模型在低资源语种中的语音识别性能。其次,我们探索了语音数据利用、多语言学习和音素识别任务在微调阶段的应用。此外,我们还借助相似性分析探讨了模型微调对不同Transformer层预训练表征的影响,涉及不同的预训练体系结构和15个语种。同时我们将预训练表征应用于端到端和传统混合系统,以验证前文的表征分析,并取得了更优的性能。
本文使用的低资源语种数据基本情况如下表所示。共15个语种,涵盖11个不同的语系。

预训练阶段影响因素对比
基于预训练模型的语音识别系统性能与预训练音频数据密不可分,不同的预训练架构也会带来性能差异。

预训练阶段影响因素(预训练数据、预训练架构)
我们比较了一些现有的开源预训练模型,以 探索不同预训练数据集和预训练架构对低资源小语种语音识别性能的影响 ,主要模型的基本情况如下表所示。

预训练数据
为保证实验的公平性,在对比不同数据集训练得到的预训练模型时,我们选择了四个wav2vec2.0模型,包括一个英语单语种模型和三个多语种模型。
对于OpenASR21数据集中的15种语言,我们从每个语系中选择一个语种作为代表,分别使用10h标注数据微调wav2vec2.0预训练模型。标注文本建模单元为字母或字素,并额外加入词分隔符。实验结果如下表所示。

通过表中结果可以发现,XLSR-128预训练模型在各个语种中均取得最低词错误率。在三个LARGE模型中,用英语音频训练得到的w2v-EN-60k模型明显处于劣势。在BASE模型和LARGE型模型之间的比较中,多语言BASE模型CLSRIL-23相比于英语LARGE模型w2v-EN-60k然使用的总训练音频量更少,但在10个语种中的9个语种上优于后者,以上结果说明了在小语种语音识别任务上,语音数据分布情况(多语种)相比于总数据量更为重要;使用更多语种更大数据量训练得到的模型性能相对更优。


不同预训练模型在微调前后各层输出表征的相似度
为了探究微调前后模型各层参数的变化情况,我们采用CKA方法对预训练模型不同位置Transformer的输出表征进行了相似度分析,如上图所示,坐标轴数字为Transformer层的索引。可以发现各个预训练模型最后几层的输出表征在微调前后都发生了较明显变化,这表明在靠近输出端的层中可能蕴含更多的语义或文本相关的高层信息,与下游任务、语种特性紧密相关。相反地,在微调后,靠近输入端的前几层表征保留了更多的原预训练模型信息,同时前几层输出表征之间的相似性较高,这也表明这些层中可能存在一定的冗余部分。由于我们更关注对应层的表征在微调后的变化情况,因此将热度图中的左下角到右上角这一对角线的情况借助折线图展现出来。可以发现不同语种之间的表征变化情况差异较小,而BASE模型和LARGE模型的变化趋势存在较明显差异。
进一步,我们将各个语种得到的相似度取平均值后展示在下图中,以更加直观地对比不同模型之间的差异。对比三个LARGE模型(w2v-EN-60k、XLSR-53、XLSR-128),我们发现模型在最后几层的相似度大小与模型的语音识别性能之间可能存在一定联系,即折线越靠上,说明对应表征的相似性越高、微调前后参数变化小,则对应的识别结果越好。

预训练架构:wav2vec2.0, HuBERT和WavLM
为了保证公平性,我们选择了三个使用相近预训练语料库和模型参数的开源预训练模型w2v-EN-60k、HuBERT-EN-60k和WavLM-EN-94k作为研究对象。其中w2v-EN-60k和HuBERT-EN-60k通过Libri-light数据集的6万小时英语数据训练得到。WavLM-EN-94k则额外使用了1万小时Gigaspeech和2.4万小时VoxPopulil数据集进行模型预训练。
实验包括两组系统设置,分别为FT和FE,其中FT指的是直接通过CTC准则进行模型微调,FE则表示将预训练模型作为前端特征提取模块用于CTC/Attention混合端到端系统。对应15个语种的语音识别结果如下表所示。

通过上表中结果我们可以发现WavLM-EN-94k模型在FT和FE系统中的15个语种的词错误率均取得了最低值。在微调FT系统中,WavLM-EN-94k预训练模型与w2v-EN-60k和HuBERT-EN-60k相比,平均词错误率分别降低了18.7%和12.3%,这也说明了在低资源小语种语音识别任务上WavLM相比于wav2vec2.0和HuBERT模型具有明显优越性。同样地,我们把以上微调之后的三个预训练模型两两之间的各层表征之间的相似度情况展示如下。可以发现模型之间的主要差别集中最后三层,HuBERT和WavLM两者之间相似度更高,随着模型层数增加,不同语种之间的差异也逐渐拉大。

同时我们发现wav2vec2.0和HuBERT模型在不同系统和不同语种上的表现存在一定区别。直接微调时,使用HuBERT模型在gn、jv、ku、so、sw和tl这6种语言上的词错误率更低,其余语种词错误率则高于wav2vec2.0模型,且有较大差距;而在FE系统中,HuBERT模型在所有15个语种中均表现更优。因此我们推测wav2vec2.0和HuBERT模型对语种或某些语言特征存在偏好。我们通过调查各个语种的基本信息发现,6个在HuBERT模型表现更优的语种均使用拉丁书写体系,而其余10种语言除越南语外没有拉丁书写系统。从音素集角度来看,前面提到的6个语种平均音素数量较少,约占其余10个语种的80%。
为了全面对比三个预训练模型微调前后的变化情况,并涵盖不同语种的差异情况,我们进行了CKA相似性分析将结果展示在下图中,其中相同颜色的多条曲线对应使用同一预训练模型的不同语种。可以看到wav2vec2.0模型相比于其他模型对于微调的变化更加明显。

微调策略
模型微调是将预训练模型用于目标下游任务的一种快捷有效方法。针对低资源小语种,为了进一步提高语音识别任务性能,我们探索了多种微调策略:无标注音频数据利用、多语种微调和音素识别任务辅助。下图中分别展示了常规微调和三种策略的流程示意。

由于预训练模型是多语种的,因而在一定程度上具有多语言的通用性,但对于特定目标语种的针对性有所不足。我们提出FT2策略以借助目标语种的语音数据将预训练模型迁移到目标语种中,使用的音频数据来自BABEL数据集。在第一阶段,我们先通过对比损失和码本多样性损失以自监督的方式微调整个模型。第二阶段,我们使用该语种的标注10h数据对第一阶段得到的模型进行CTC准则微调。两阶段微调方法有助于预训练模型有效地适应单一目标语种。下表中展示了传统混合系统和微调系统FT、两阶段微调系统FT2的语音识别结果,可以看到FT2系统借助额外无标注语音数据取得了明显性能提升。从平均值来看,我们提出的策略相比于传统最优混合单系统在词错误率上可以相对降低8.5% 。

在另外两个策略上,我们通过实验验证了单语种微调相比于多语种微调的性能优越性,前者凭借更高的语种针对性在目标语种的语音识别任务上能够取得更优的性能,而后者则帮助模型学习更加通用鲁棒的表征。我们也借助实验说明了音素识别任务对于语音识别任务的辅助作用,且提升效果在低资源条件下更为明显。
基于预训练模型的其他系统框架
表征学习是机器学习中一种流行方法,不同表征往往可以揭示在数据背后隐藏的不同层面可解释因素。我们采用自监督预训练模型作为模型主干或用于提取表征,重点讨论低资源ASR任务中不同Transformer块的输出表征,系统框架包括CTC/Attention端到端系统和传统NN/HMM混合系统,如下图所示。

端到端系统
近期基于Transformer和Conformer的端到端ASR系统凭借其优异性能备受关注。但由于数据驱动的特性对低资源条件下的应用有所受限。借助预训练模型则可以应对标注数据资源不足带来的挑战,从而发挥端到端系统的性能优势。
将预训练模型应用于端到端系统有两种方法:第一种是把预训练模型作为编码器部分,在此基础上添加基于Transformer的解码器来构建完整的encoder-decoder系统;第二种则是将预训练模型作为前端模块来提取表征,将提取到的表征输入到端到端系统进行模型训练。上述两种方法分别记为为EN和FE。通过实验发现前者性能表现欠佳,因此主要采用后者进行后续探索。
DNN/HMM混合系统混合系统
在传统混合系统中,我们依旧将预训练模型作为特征提取器。将音频数据输入到预训练模型中,从指定的Transformer层中提取表征,作为声学模型的特征进行使用。

实验使用波斯语数据集,为方便对比我们将不同系统使用不同预训练模型各层表征的语音识别性能情况展示在上图中。可以看到,从预训练模型的第18层到第21层Transformer提取表征对于ASR任务相对更有利。微调后预训练模型XLSR-53-FT取得了最低的词错误率,同时对比微调后的模型XLSR-53-FT和原预训练模型XLSR-53,主要差异集中在最后3层,后者的最后3层表征在端到端和传统混合系统中均表现出明显的性能下降。从图中折线变化来看,WavLM和微调后的wav2vec2.0模型XLSR-53-FT趋势一致,而HuBERT则和XLSR-53更加接近。此外,相比于传统混合系统,端到端系统对来自不同预训练模型或同一预训练模型中不同层的表征更为敏感。
总结
本文将wav2vec2.0,HuBERT和WavLM自监督预训练模型应用于低资源语种语音识别系统中,在10小时标注数据集的条件下对15个低资源小语种的识别性能进行提升。研究包括预训练模型使用的数据和体系架构、微调方法、预训练表征提取与分析、以及在端到端和混合系统中的进一步应用。
我们发现,目标语种的音频数据对于预训练模型的迁移应用具有明显帮助作用,借助自监督训练进行模型微调可以使得预训练模型更好地适应目标语种。多语言预训练模型在跨语种语音识别中具有优势,但多语种微调相比于单语种微调并未取得性能提升。我们通过实验验证了音素识别任务可以提高低资源语音识别的性能。
同时我们也深入分析了预训练模型各个Transformer层输出表征之间的关系,了解不同语种、不同预训练模型、不同微调方法带来的变化。并进一步在端到端和传统混合系统中对预训练表征进行了对比和应用。