


|
个人信息Personal Information
教师英文名称:Wei-Qiang Zhang
教师拼音名称:Zhang Wei Qiang
电子邮箱:
办公地点:电子工程馆5-111
联系方式:010-62781847
学位:博士学位
毕业院校:清华大学
学科:信号与信息处理
DistilXLSR:压缩的多语种语音表征模型
点击次数:
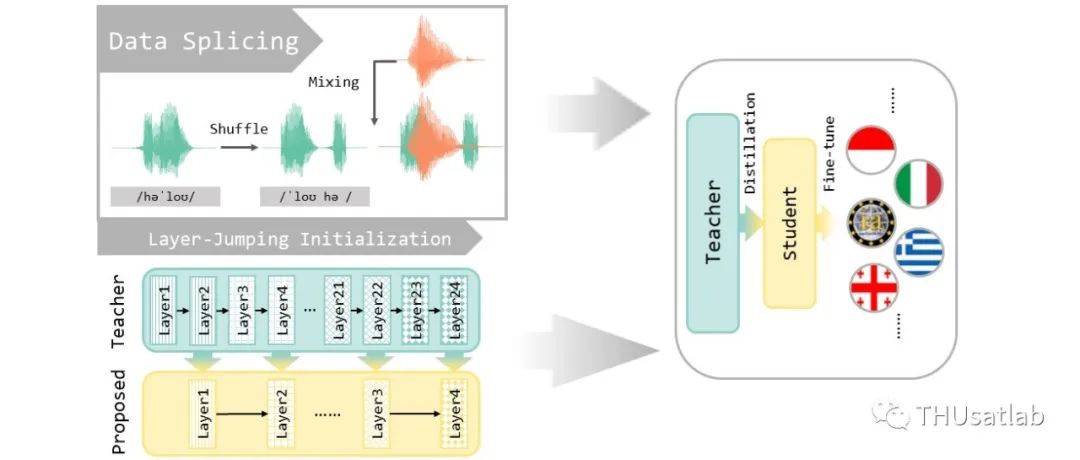
低资源语言的语音识别一直是语音领域的热点问题,而多语种预训练模型的出现则极大提升了各类低资源任务的表现。在包含各种语言的大规模数据集进行的预训练能帮助模型提取稳定的、易于学习的表征,从而大幅提升语音识别的准确率。然而,现有的多语种模型一般参数量较大,不适合部署在端上。本文介绍清华大学语音与音频技术实验室在INTERSPEECH 2023上发表的论文《DistilXLSR: A Light Weight Cross-Lingual Speech Representation Model》。作者对XLSR-53和XLSR-128等多语种大模型进行了蒸馏,通过跳层初始化更好地利用预训练参数,并通过数据拼接摆脱蒸馏过程中对多语种数据的依赖。
一、多语种预训练模型及其蒸馏
目前广泛使用的预训练模型包括XLSR-53、Voxpopuli-100k、XLS-R系列模型等等。这些模型通常在几十个语种的几万到几十万小时数据上进行预训练,参数量在300M到2B不等。尽管这些模型在各种低资源任务上有良好的表现,但对硬件计算能力的要求同样较高。
知识蒸馏是模型压缩领域广泛使用的策略之一。知识蒸馏技术使用预训练模型作为教师模型,要求较小的学生模型模仿教师模型各层的输出或是在特定任务上的输出概率分布。在预训练的教师模型的指导下,学生模型的学习过程会更加平滑,收敛效果也更好。
在这篇文章中,我们使用一个12层的Transformer模型作为学生,以24层的XLSR-53和XLS-R 300M两种模型作为教师,从而压缩近一半的参数。我们使用教师和学生模型的中间特征之间的均方误差损失作为蒸馏目标,从而得到不特定于任务、跨语种通用的模型。
二、跳层初始化
模型蒸馏中,学生模型的初始化参数通常是随机的,或是与教师模型的较低几层参数保持一致(例如,12层的学生模型,就使用教师模型的前12层参数初始化)。但是,我们观察到XLSR-53模型的各层参数有着十分复杂的关系。

左:Wav2vec2 base模型的内积相似度 右:XLSR-53模型的内积相似度
上图表示Wav2vec2 base和XLSR-53模型各层参数的内积相似度,颜色越浅相似度越高。可以看到,相比浅层的Wav2vec2 base模型,XLSR-53模型的层间相似度呈“X”形,即每层不仅与相邻的层相似,也与相隔几层的其他层相似;另外,模型的最后几层是独特的,不与其他任何层相似。
这种情况下,如果仅使用XLSR-53的前12层参数初始化学生模型,靠蒸馏重构这种复杂的相似关系会非常困难,不利于学生模型的学习。因此,我们提出了一种跳层初始化方式,使用教师模型的偶数层(从0计数)来初始化学生模型,以更充分地利用预训练的参数。
三、数据拼接
多语种蒸馏的一个问题是多语种数据的采集成本过高,因此,我们考虑仅使用资源丰富语种(如英语)的数据来蒸馏多语种模型。
目前的研究认为,语音中的语种信息来源于音素的排列顺序,如果以音素为单位将语音打乱后重新拼接,就可以大幅度移除语种信息。我们将这种方法称为数据拼接。
实验中,我们先将语音与标注强制对齐,从对齐结果中获得音素级时间戳。为了避免多个辅音连续出现等不符合语音规律的情况,我们以音节为单位做了随机打乱和拼接,使用这种数据进行语种无关的蒸馏。
四、实验结果概览

蒸馏模型与教师模型(XLSR-53)、两个英语大模型(w2v-EN-60k/HuBERT-EN-60k)的性能对比
上图展示了我们仅使用英语数据蒸馏的模型与教师模型、其他使用英语数据预训练的大模型在多个低资源语种语音识别任务上的表现。可以看到,尽管我们的模型仅使用了英语数据蒸馏,但表现仍能打平甚至超过参数量翻倍的英语预训练模型,这表明跨语种的表征能力在蒸馏后仍被保留。

左:不使用跳层初始化内积相似度 右:使用跳层初始化的内积相似度
上图展示了使用跳层初始化前后蒸馏模型的层间相似度变化。可以看出,跳层初始化有助于学生模型更好地学到XLSR-53的层间相似度关系。
限于篇幅原因,我们省略了部分实验结果。有关完整的结果图表,请参考论文全文。
五、结论
我们提出了一种多语种语音预训练模型的蒸馏方法,通过跳层初始化充分利用预训练模型参数,并通过数据拼接实现仅使用英语数据 的模型蒸馏。实验表明,我们的模型在参数量减少一半的情况下仍能保持跨语种的表征能力。
论文链接:https://www.isca-speech.org/archive/interspeech_2023/wang23ea_interspeech.html