

Gradient-aware knowledge distillation: Tackling gradient insensitivity through teacher guided gradient scaling
Release time: 2025/12/29
Hits:
- DOI number:
- 10.1016/j.neunet.2025.108229
- Journal:
- Neural Networks
- Abstract:
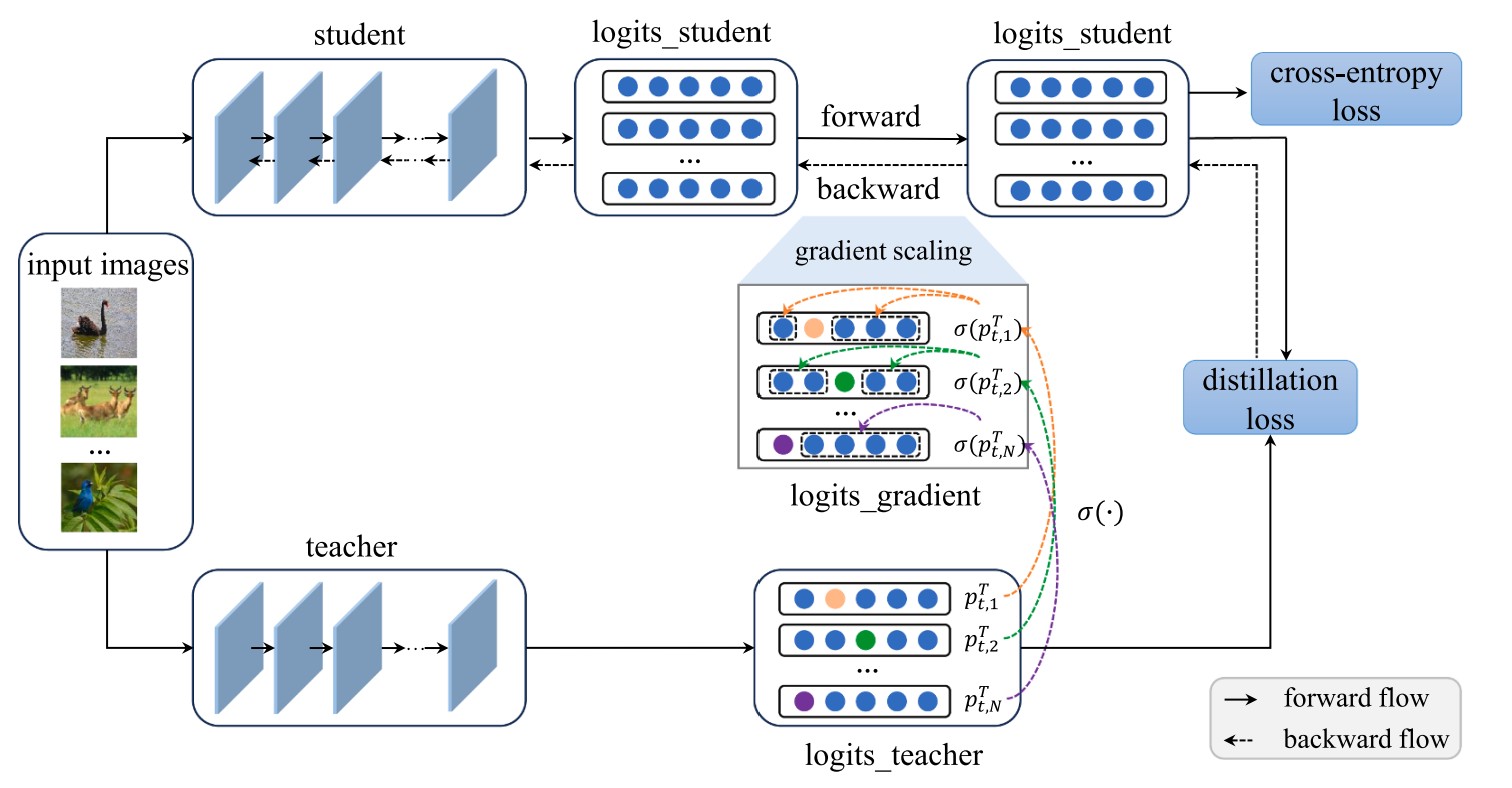
- Prior research on knowledge distillation has primarily focused on enhancing the process through logits and feature-based approaches. In this paper, we present a novel gradient-based perspective on the learning dynamics of knowledge distillation, revealing a previously overlooked issue of gradient insensitivity. This issue arises when the varying confidence levels of the teacher’s predictions are not adequately captured in the student’s gradient updates, hindering the effective transfer of nuanced knowledge. To address this challenge, we propose gradient-aware knowledge distillation, a method designed to mitigate gradient insensitivity by incorporating varying teacher confidence into the distillation procedure. Specifically, it adjusts the gradients of the student logits in accordance with the teacher confidence, introducing sample-specific adjustments that assign higher-weighted updates to the non-target classes of samples where the teacher exhibits greater confidence. Extensive experiments on image classification and object detection tasks demonstrate the superiority of our approach, particularly in heterogeneous teacher-student scenarios, achieving state-of-the-art performance on ImageNet. Moreover, the proposed method is versatile and can be effectively integrated with many logits distillation methods, providing a robust enhancement to existing methods. The code is available at https://github.com/snw2021/GKD.
- Co-author:
- Wenlin Zhang,Hao Zhang,Dan Qu
- First Author:
- Nianwen Si
- Indexed by:
- Journal paper
- Correspondence Author:
- Wei-Qiang Zhang,Heyu Chang
- Translation or Not:
- no
- Date of Publication:
- 2026/01/15
- Links to published journals:
- https://doi.org/10.1016/j.neunet.2025.108229