
Improving speech translation by cross-modal multi-grained contrastive learning
发布时间:2023-02-13
点击次数:
- DOI码:
- 10.1109/TASLP.2023.3244521
- 发表刊物:
- IEEE/ACM Transactions on Audio, Speech, and Language Processing
- 摘要:
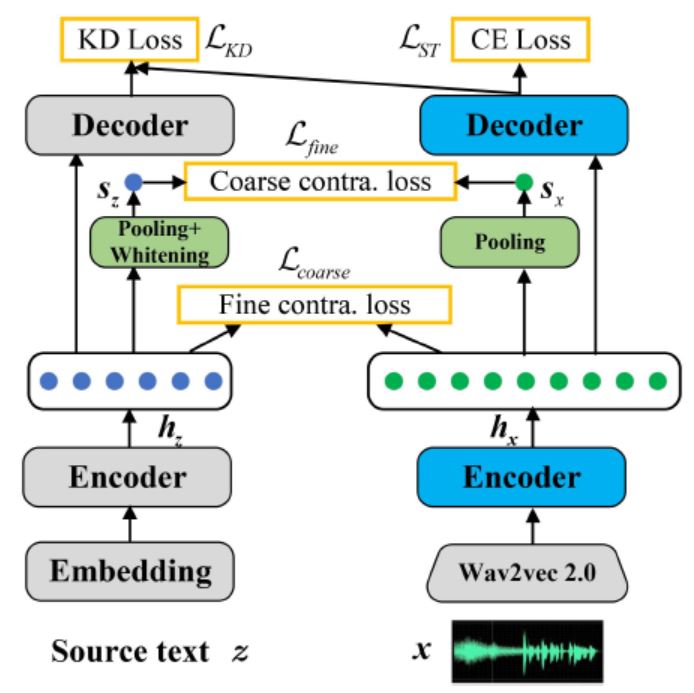
- The end-to-end speech translation (E2E-ST) model has gradually become a mainstream paradigm due to its low latency and less error propagation. However, it is non-trivial to train such a model well due to the task complexity and data scarcity. The speech-and-text modality differences result in the E2E-ST model performance usually inferior to the corresponding machine translation (MT) model. Based on the above observation, existing methods often use sharing mechanisms to carry out implicit knowledge transfer by imposing various constraints. However, the final model often performs worse on the MT task than the MT model trained alone, which means that the knowledge transfer ability of this method is also limited. To deal with these problems, we propose the FCCL ( F ine- and C oarse- Granularity C ontrastive L earning) approach for E2E-ST, which makes explicit knowledge transfer through cross-modal multi-grained contrastive learning. A key ingredient of our approach is applying contrastive learning at both sentence- and frame-level to give the comprehensive guide for extracting speech representations containing rich semantic information. In addition, we adopt a simple whitening method to alleviate the representation degeneration in the MT model, which adversely affects contrast learning. Experiments on the MuST-C benchmark show that our proposed approach significantly outperforms the state-of-the-art E2E-ST baselines on all eight language pairs. Further analysis indicates that FCCL can free up its capacity from learning grammatical structure information and force more layers to learn semantic information.
- 合写作者:
- Nianwen Si,Yaqi Chen,Wei-Qiang Zhang
- 第一作者:
- Hao Zhang
- 论文类型:
- 期刊论文
- 通讯作者:
- Xukui Yang,Dan Qu
- 是否译文:
- 否
- 发表时间:
- 2023-02-13