

Improving automatic speech recognition performance for low-resource languages with self-supervised models
Release time: 2022/06/22
Hits:
- DOI number:
- 10.1109/JSTSP.2022.3184480
- Journal:
- IEEE Journal of Selected Topics in Signal Processing
- Abstract:
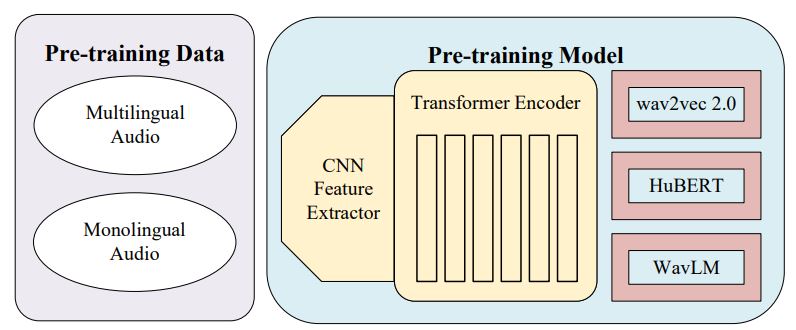
- Speech self-supervised learning has attracted much attention due to its promising performance in multiple downstream tasks, and has become a new growth engine for speech recognition in low-resource languages. In this paper, we exploit and analyze a series of wav2vec pre-trained models for speech recognition in 15 low-resource languages in the OpenASR21 Challenge. The investigation covers two important variables during pre-training, three fine-tuning methods, as well as applications in End-to-End and hybrid systems. First, pre-trained models with different pre-training audio data and architectures (wav2vec2.0, HuBERT and WavLM) are explored for their speech recognition performance in low-resource languages. Second, we investigate data utilization, multilingual learning, and the use of a phoneme-level recognition task in fine-tuning. Furthermore, we explore what effect fine-tuning has on the similarity of representations extracted from different transformer layers. The similarity analyses cover different pre-trained architectures and fine-tuning languages. We apply pre-trained representations to End-to-End and hybrid systems to confirm our representation analyses, which have obtained better performances as well.
- First Author:
- Jing Zhao
- Indexed by:
- Journal paper
- Correspondence Author:
- Wei-Qiang Zhang
- Translation or Not:
- no
- Date of Publication:
- 2022/06/20
- Links to published journals:
- https://ieeexplore.ieee.org/document/9801640